quorai quorai
quorai quorai Quorai is a research sandbox for AI-driven investment analysis. Twenty-five language-model agents — investor personas paired with quant, sentiment, and valuation specialists — are sorted into six schools of thought. Each school weighs its members by conviction, not by headcount; when the schools disagree, the disagreement itself becomes the signal. Nothing is ever actually traded.
Quorai is not a product. It's a small open-source repo exploring one idea: can structured disagreement between LLM agents produce more honest trading signals than a single model talking to itself?
The name blends quorum — a deliberating body — with AI. That is the system's core mechanic: each agent embodies a known investment philosophy (Graham's margin of safety, Simons' stat-arb, Dalio's debt-cycle lens, and so on) and analyses the same ticker independently. The agents are sorted into six schools of thought; within each school, members' signals are combined weighted by conviction — not by headcount — into a single stance. When schools disagree, a moderator surfaces the split before a portfolio manager turns the result into a buy / sell / hold.
The project is inspired by virattt/ai-hedge-fund and TauricResearch/TradingAgents. It's meant as a study aid and a place to compare prompting strategies — not as a recommendation engine. No real orders are ever placed.
Two optional layers shape which agents run and how much weight they carry. A market-regime classifier reads the current SPY trend each morning and narrows the active analyst subset to the groups most relevant to that regime — reducing noise and token cost on bear or risk-off days. A conviction-weight feedback loop tracks each agent's rolling directional hit-rate across labelled historical signals and proportionally upweights the most accurate voices in the debate aggregation on the next run.
Quorai is one of several open-source multi-agent LLM trading projects. The two most-cited reference points are virattt/ai-hedge-fund — the popular persona-agent demo with a bundled web UI — and TauricResearch/TradingAgents — the LangGraph research framework behind arXiv:2412.20138. Quorai borrows from both and diverges from both.
| Area | ai-hedge-fund | TradingAgents | Quorai |
|---|---|---|---|
| Agent roster | 13 personas + 4 analytical + risk + PM | 4 analysts + Bull/Bear researchers + Trader + Risk team + PM | 25 personas across 6 schools + analytical agents |
| Orchestration | Sequential agent workflow | LangGraph StateGraph | LangGraph StateGraph with parallel analyst fan-out |
| Debate mechanism | — | Bull vs Bear structured debate (max_debate_rounds configurable) | 6 strategy-group aggregation (confidence-weighted) + LLM moderator on contested tickers only |
| Reflection / memory | — | ✅ Decision log with realised return + alpha-vs-SPY injected into next run's Portfolio Manager prompt | ✅ Per-agent rolling hit-rate from forward-return labelling drives next run's debate weights |
| Point-in-time SEC EDGAR | — | — | ✅ Local SQLite XBRL cache; eliminates yfinance look-ahead bias on historical share counts and financials |
| Market regime gate | — | — | ✅ Daily SPY regime classifier (bull / bear / risk-off / neutral) gates active analyst subset and filters proposed orders |
| A/B comparison harness | — | — | ✅ backtester compare — side-by-side metrics for regime-on vs off, uniform vs conviction weights |
| Live / paper trading | Backtest only ("does not actually make any trades") | Backtest / simulated exchange only | ✅ Alpaca paper trading (live keys hard-blocked at the client layer) |
| Human approval gate | — | — | ✅ Telegram approve/reject per cycle + command inbox (pause, only-sells, skip-next, resume) |
| Risk controls | Single Risk Manager agent | Risk Management Team agents | ✅ 5 preset profiles bundling position sizing + per-order notional / qty / daily-loss caps |
| Per-agent model routing | — | Two-tier: deep_think_llm / quick_think_llm | ✅ Per-analyst override (--agent-model AGENT=model/PROVIDER) |
| Token telemetry + prompt caching | — | — | ✅ Per-agent input / output / cache tokens accumulated across the run; Anthropic prompt cache surfaced separately |
| Parallel ticker execution | — | — | ✅ Thread-pool fan-out via QUORAI_PARALLEL_TICKERS=N |
| Checkpoint / resume | — | ✅ LangGraph checkpoint per ticker (--checkpoint) | — |
| LLM provider coverage | OpenAI, Anthropic, Groq, DeepSeek, Ollama | OpenAI, Google, Anthropic, xAI, DeepSeek, Qwen, GLM, MiniMax, OpenRouter, Ollama, Azure | 14 providers: OpenAI, Anthropic, Groq, Gemini, DeepSeek, xAI, OpenRouter, Ollama (local / free), Alibaba, Azure, GigaChat, Meta, Mistral, Kimi + per-agent overrides |
| LLM-vs-math measurement | — | — | ✅ Deterministic math twin per agent; agreement rate, override accuracy, ΔIC / Δhit-rate / Δalpha "LLM premium"; auto-run after every backtest |
| Realistic cost model | — | — | ✅ Optional slippage / commission / short-borrow bps flow through NAV into Sharpe and alpha (--slippage-bps, --commission-bps, --borrow-bps-annual) |
| Docker | — | ✅ | — |
| Academic paper | — | ✅ arXiv:2412.20138 | — |
| Web UI | ✅ Bundled, full-featured | — (CLI / TUI only) | Separate read-only inspector (quorai-ui) |
| MCP server | — | — | ✅ quorai-mcp via uvx — full analyst panel callable from Claude Code, Cursor, Cline, and any MCP host |
Comparison based on the public ai-hedge-fund and TradingAgents
READMEs at the time of writing. Corrections welcome via PR.
A single ticker traverses the graph below once per trading day. Boxes are deterministic where the maths allows; only those that need judgement call an LLM.
Each trading day the pipeline optionally classifies the current SPY regime (bull / bear / risk-off / neutral) and loads per-agent conviction weights built from prior labelled runs.
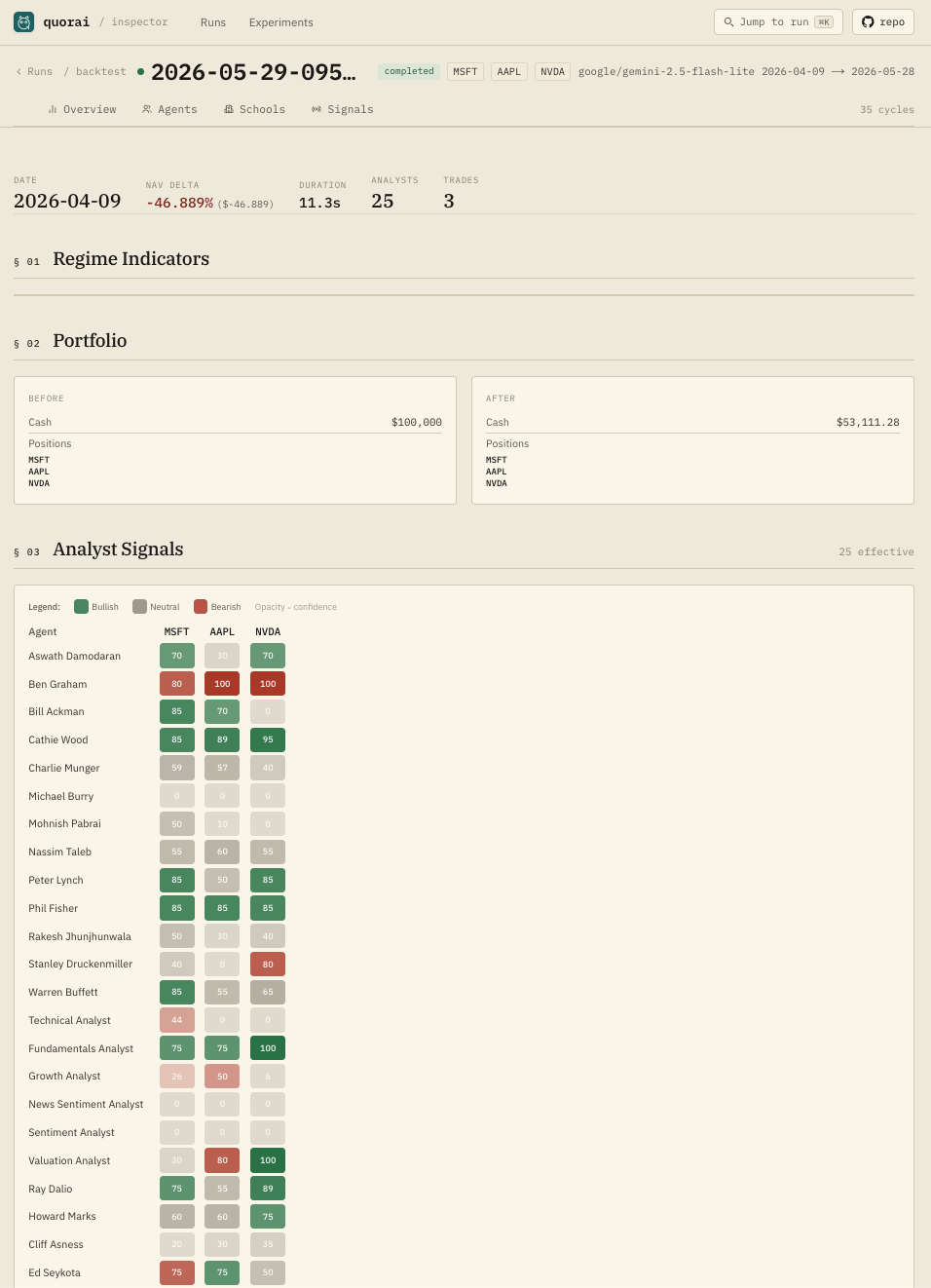
Each persona independently analyses each ticker from price history, fundamentals, insider trades, and news. When regime selection is active, only groups relevant to the current regime run — e.g. risk-off routes to macro, deep value, and sentiment.
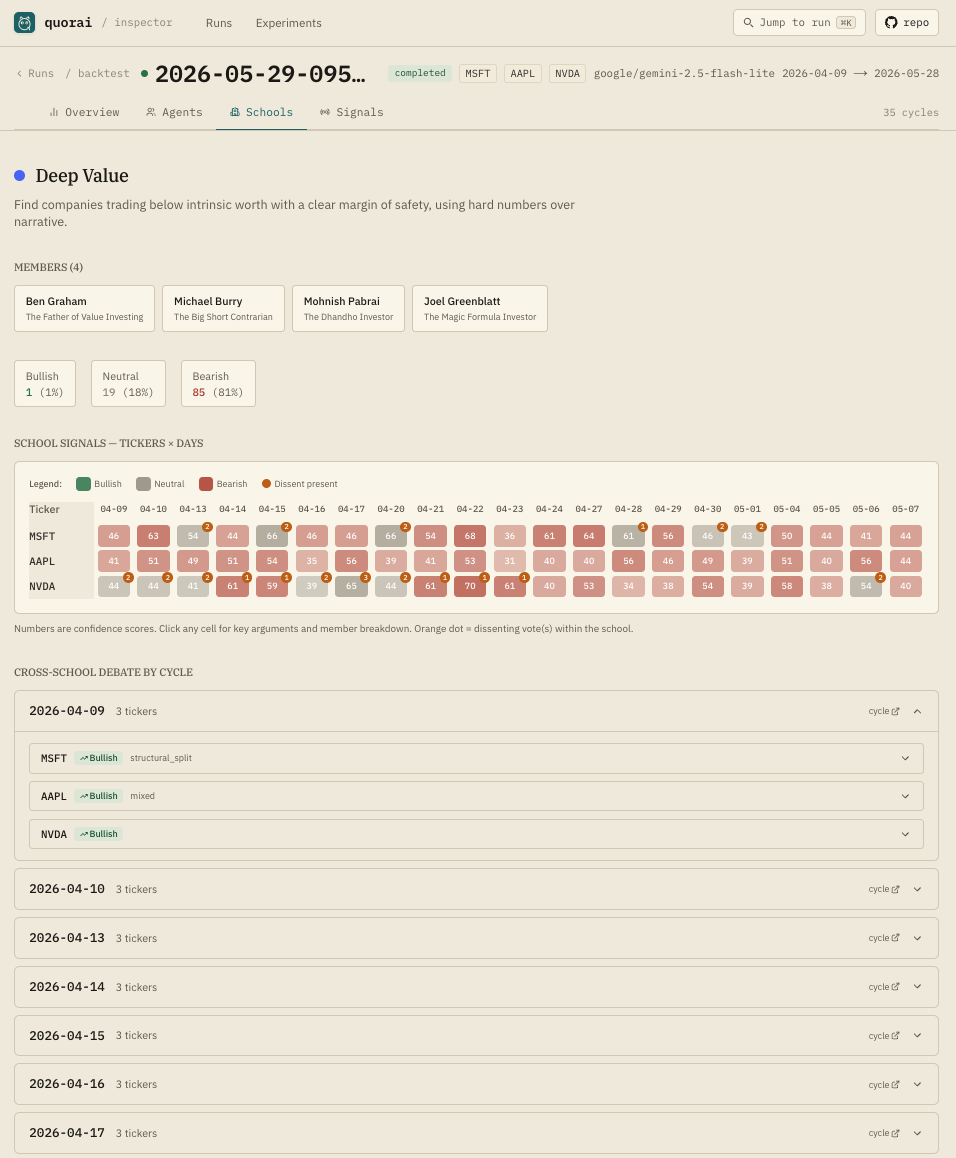
Within each of the six schools, members' signals are confidence-weighted
(optionally multiplied by their rolling conviction score via
--use-conviction-weights) and averaged into a group stance:
≥ +0.25 → bullish, ≤ −0.25 → bearish, otherwise neutral. Only when at least
one school is bullish and another is bearish on the same ticker does
an LLM moderator fire to name and summarise the split.
Volatility- and correlation-adjusted position limits are computed deterministically, so an excitable agent can't oversize a bad idea.
The portfolio manager emits a buy / sell / hold decision with sizing
and reasoning. Per-agent signals are written to a JSONL log. To close the
feedback loop, run the backtester feedback subcommand after each
run to label signals with 1 d / 5 d / 20 d forward returns and write
weights.json; then pass --use-conviction-weights on
the next run.
Six schools of thought, twenty-five personas. Each persona has a fixed prompt; the pull-quotes summarise the lens they argue from.
Find companies trading below intrinsic worth with a clear margin of safety, using hard numbers over narrative.
Long-term ownership of durable franchises with strong moats, exceptional management, and compounding economics.
Disruptive innovation, activist catalysts, and outsized growth potential at a price the market hasn't yet recognised.
Top-down regime analysis — debt cycles, liquidity flows, and tail-risk awareness — to time and size positions.
Rule-based factor models, trend-following, and statistical arbitrage — data decides, narrative is noise.
Bottom-up specialists in fundamentals, valuation, growth signals, and market-sentiment indicators.
The schools argue in natural language, but each analyst calls into a small Python library that does the actual arithmetic. Two pieces are worth surfacing: how positions are sized, and how intrinsic value is estimated.
Every ticker gets a base notional limit, then two independent multipliers are applied.
First, realised volatility — annualised as std(60-day returns) × √252 —
buckets the name into one of four tiers:
| Annualised vol | Multiplier |
|---|---|
| < 15 % | 1.25× |
| 15 – 30 % | 1.0 − (vol − 0.15) × 0.5 |
| 30 – 50 % | 0.75 − (vol − 0.30) × 0.5 |
| > 50 % | 0.50× |
Second, the average correlation with already-open positions scales the limit again — concentrated bets get cut, uncorrelated additions get a small boost:
| Avg correlation | Multiplier |
|---|---|
| ≥ 0.80 | 0.70× |
| 0.60 – 0.80 | 0.85× |
| 0.40 – 0.60 | 1.00× |
| 0.20 – 0.40 | 1.05× |
| < 0.20 | 1.10× |
Final limit: base_limit × vol_multiplier × corr_multiplier, then clamped
to available cash and margin.
The valuation agent runs four methods in parallel and blends their outputs.
Owner Earnings (Buffett): net_income + D&A − capex − Δworking_capital,
projected ten years, discounted to present value, then haircut 25 % for margin of
safety. DCF: Σ FCF_t / (1+r)^t + TV / (1+r)^n with
terminal value TV = FCF_n × (1 + g) / (r − g).
EV/EBITDA cross-check:
implied_equity = median_sector_EV/EBITDA × current_EBITDA − net_debt.
Residual income (Edwards-Bell-Ohlson):
RI_t = net_income_t − cost_of_equity × book_value_{t−1}, summed in
present-value terms on top of current book value.
The four estimates are blended at fixed weights —
DCF 35 % · Owner Earnings 35 % · EV/EBITDA 20 % · Residual Income 10 %
— and the gap (weighted_intrinsic − market_cap) / market_cap drives
the signal at a ±15 % threshold.
The DCF agent runs three growth phases (high, fade, terminal) discounted at WACC.
Before discounting, a quality adjustment scales the projected cash flows:
quality_factor = max(0.7, 1 − fcf_volatility × 0.5) where
fcf_volatility = std(FCF) / mean(FCF) (coefficient of variation).
A scenario overlay then weights bear / base / bull growth assumptions at
20 % / 60 % / 20 % to capture tail outcomes without
over-engineering the base case.
cost_of_equity = RF + β × MRP (RF = 4.5 %, MRP = 6 %, β from
TTM metrics). Cost of debt:
max(RF + 0.01, RF + 10 / interest_coverage). Final WACC:
(E/V) × CoE + (D/V) × CoD × (1 − 0.25), floored at 6 % and
capped at 20 % to keep the discount rate within a plausible range regardless of
data quality.
Every per-agent, per-ticker signal written to the JSONL log can be labelled with
1 d / 5 d / 20 d forward returns via the backtester feedback
subcommand. A rolling per-agent directional hit-rate is computed from those
labels and serialised to src/feedback/weights.json. On the next
run, passing --use-conviction-weights loads those weights and
multiplies each agent's confidence by its historical accuracy before the debate
aggregation — so agents that have been right proportionally louder.
Every instrumented persona analyst computes a deterministic "math twin" signal from
its underlying quantitative inputs before making an LLM call. The score
maps to a direction via per-agent calibrated thresholds (defaults:
bull_cut = 0.60, bear_cut = 0.40) and is written to the
signal log alongside the LLM signal and confidence — so
both can be compared per agent, per ticker, and across the full run.
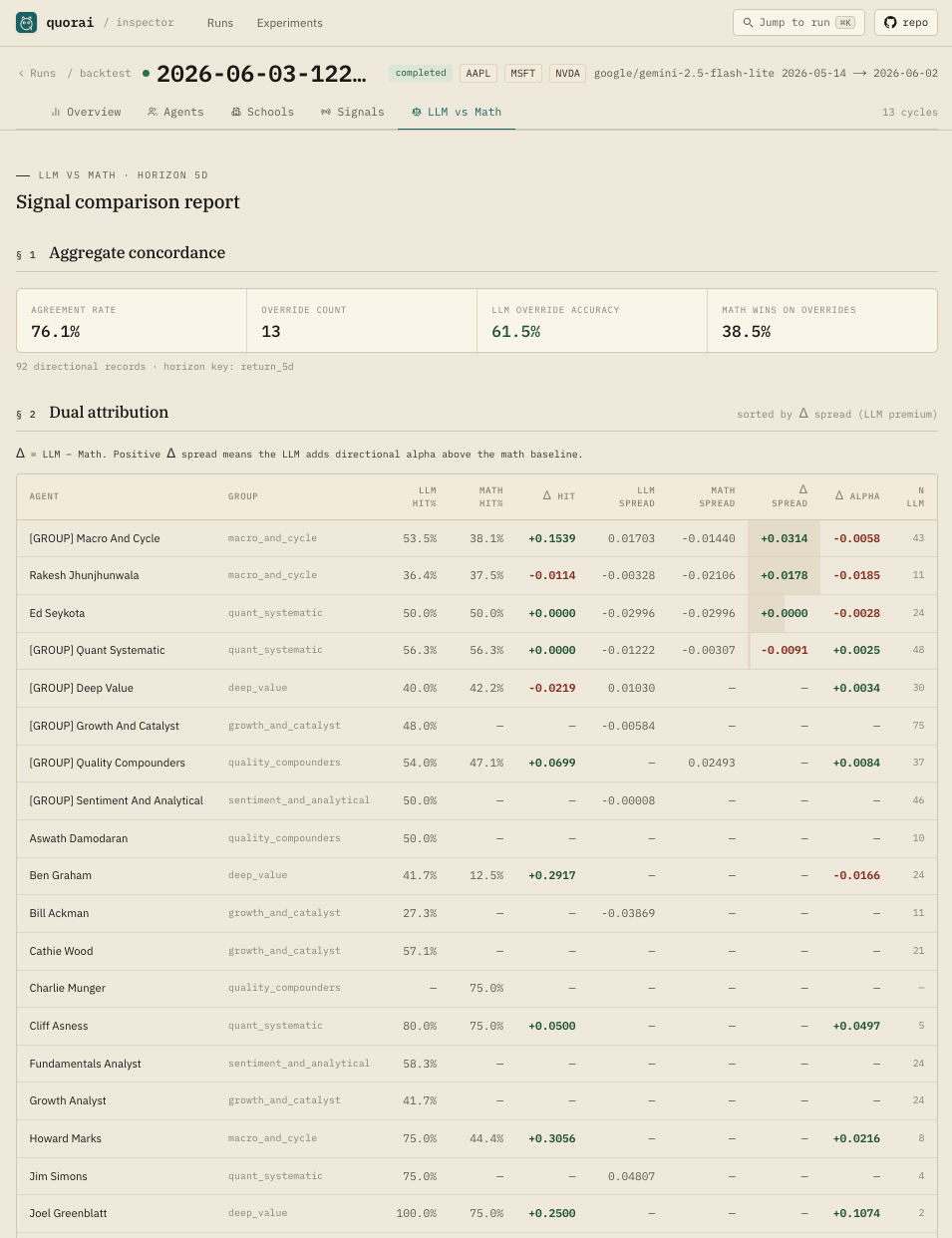
The backtester llm-vs-math subcommand computes the following per agent
from a labelled signal log:
| Metric | Definition |
|---|---|
| Agreement rate | agree / total_directional — fraction of (bullish/bearish) records where signal == math_signal |
| Override count | Records where the LLM direction differs from the math twin |
| LLM override accuracy | llm_correct / override_count — among overrides, fraction where the LLM direction matched the forward-return sign |
| Math win rate on overrides | Fraction of overrides where math was right and LLM was wrong |
| Δhit-rate | llm_hit_rate − math_hit_rate per agent — LLM premium on directional accuracy |
| Δspread (IC) | llm_directional_spread − math_directional_spread — LLM premium on signal information coefficient |
| Δalpha | llm_alpha_vs_baseline − math_alpha_vs_baseline per agent |
The backtester debate-impact subcommand replays group aggregation on
both LLM and math-twin signal sets per stored cycle bundle and reports the
mean |tilt delta| (LLM vs math panel stance), contested-set Jaccard overlap, and
per-school group-stance flip rate. Together these answer: how much does the debate
change what the math alone would have decided?
Every backtester run automatically executes a 3-step analytics suite
after the backtest completes:
feedback/weights.json.backtester feedback once the horizon has elapsed.
Each step is guarded — an analytics failure prints a warning but never crashes the
run. Pass --no-analyze to skip the suite entirely. The two heavier
remaining steps (calibrate-math and llm-ablation) are
printed as copy-pasteable commands at the end of each run rather than run
automatically.
backtester llm-ablation reruns the backtest under several modes and
reports P&L, Sharpe, drawdown, and token cost for each:
QUORAI_PM_MODE=rule — portfolio manager replaced by a deterministic tilt-following rule; no PM LLM call.QUORAI_PM_DEBATE_CONTEXT=0 — PM prompt omits the debate-moderator summary.--full-loo) — each persona is individually replaced by its math twin to quantify its marginal contribution.
Math-twin thresholds can be calibrated from any labelled signal log:
backtester calibrate-math grid-searches per-agent
bull_cut / bear_cut values to maximise directional spread
and writes results to feedback/math_thresholds.json.
The Alpaca client refuses to construct a live-trading client unless
ALPACA_PAPER=True. That single check is the base safety net;
everything else is layered on top of it.
Pass --risk-profile to bundle four related caps in one flag.
Individual caps are still overridable via env vars for a single run.
| Profile | base_limit | Notional cap | Qty cap | Daily loss limit |
|---|---|---|---|---|
conservative | 10 % | $5,000 | 500 shares | 2 % |
cautious | 15 % | $7,500 | 750 shares | 3 % |
balanced (default) | 20 % | $10,000 | 1,000 shares | 5 % |
aggressive | 30 % | $20,000 | 2,000 shares | 8 % |
speculative | 50 % | $50,000 | 5,000 shares | 15 % |
Add --require-approval to send proposed orders as an inline
Telegram message before any order is submitted. The gate is fail-closed: missing
credentials, a Telegram error, a rejection, or a timeout (default 30 min) all
abort with zero orders. The bot also reads a plain-text command inbox at the
start of each run:
| Message | Effect |
|---|---|
accept only sales | Suppress all buy orders for the next run only |
skip next day | Skip the next scheduled run entirely |
pause | Pause all runs until you send continue |
continue | Clear an active pause |
Command state persists in logs/command_state.json across restarts.
Set KILL_SWITCH=true in .env to reject every order
immediately — no LLM call, no broker call — until the flag is cleared.
balanced preset) can be submitted in a
single run before any cap fires.
0.000 shares and is classified as
skipped with no warning.
--catch-up to recover the prior-close equity from Alpaca's
portfolio history instead.
Clone the repo, install with uv sync, and invoke one of the entry points
below. You'll need a key for at least one LLM provider plus a Finnhub key for market
data.
uv run backtester --tickers AAPL,MSFT --model deepseek/deepseek-chat --model-provider OpenRouter --show-reasoning
uv run backtester --tickers AAPL,MSFT --model deepseek/deepseek-chat --model-provider OpenRouter --risk-profile speculative
uv run backtester --tickers AAPL,MSFT --model deepseek/deepseek-chat --model-provider OpenRouter --use-regime-selection --use-conviction-weights
uv run backtester feedback --signal-log logs/backtest/signals/signals-<run-id>.jsonl # writes weights.json
uv run backtester compare --mode both --tickers AAPL,MSFT --model deepseek/deepseek-chat --model-provider OpenRouter
uv run python src/live_trading.py --tickers AAPL,MSFT --model deepseek/deepseek-chat --model-provider OpenRouter --require-approval --dry-run
claude mcp add quorai uvx quorai-mcp
uv run backtester --tickers AAPL,MSFT --model deepseek/deepseek-chat --model-provider OpenRouter --slippage-bps 5 --commission-bps 1 --borrow-bps-annual 50
uv run backtester calibrate-math --signal-log logs/backtest/signals/signals-<run-id>.jsonl # grid-searches per-agent bull_cut / bear_cut
uv run backtester llm-ablation --tickers AAPL,MSFT --start-date 2026-01-01 --end-date 2026-03-31 # reruns with all-math / PM-rule / no-debate-context modes
--risk-profile accepts conservative, cautious,
balanced (default), aggressive, or speculative
— each preset bundles position-sizing limits, order-notional caps, and a daily loss
limit. --use-conviction-weights requires a prior feedback
run to have produced weights.json. Live trading is paper-only by
construction (the Alpaca client refuses to connect to a live endpoint). For
historically accurate backtests, seed the SEC EDGAR fundamentals cache first:
uv run python experiments/seed_sec_fundamentals.py --tickers AAPL,MSFT.
Every backtest automatically runs a 3-step analytics suite after the run completes
(school-debate impact → forward-return labeling → LLM-vs-math); pass
--no-analyze to opt out. The calibrate-math and
llm-ablation steps are heavier — they're printed as copy-pasteable
commands at the end of each run rather than run automatically.
See the
README
for the full setup walkthrough.
For a browsable view of the cycle bundles written to logs/, see the
read-only companion UI at
quorai/quorai-ui
(§ 09 below).
To expose the panel as a tool call to any MCP host (Claude Code, Claude Desktop, Cursor, Cline, …), run claude mcp add quorai uvx quorai-mcp — see the MCP server section of the README.
Educational and research use only. Quorai does not constitute investment advice. Agent signals are generated by language models and should not be used as the basis for real financial decisions. Past signals do not guarantee future performance.
quorai-ui
is a read-only companion web app (Next.js, runs on port 3030) that reads the cycle bundles
quorai-app writes to logs/<mode>/runs/ and presents them
as browsable, comparable views. It never touches the trading system — point it at the
logs/ directory and go.
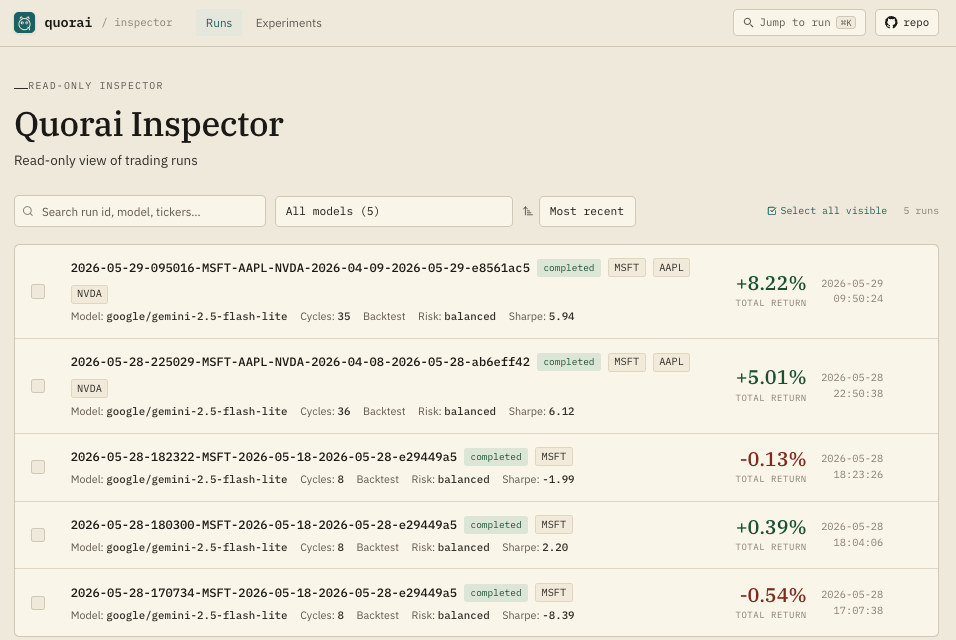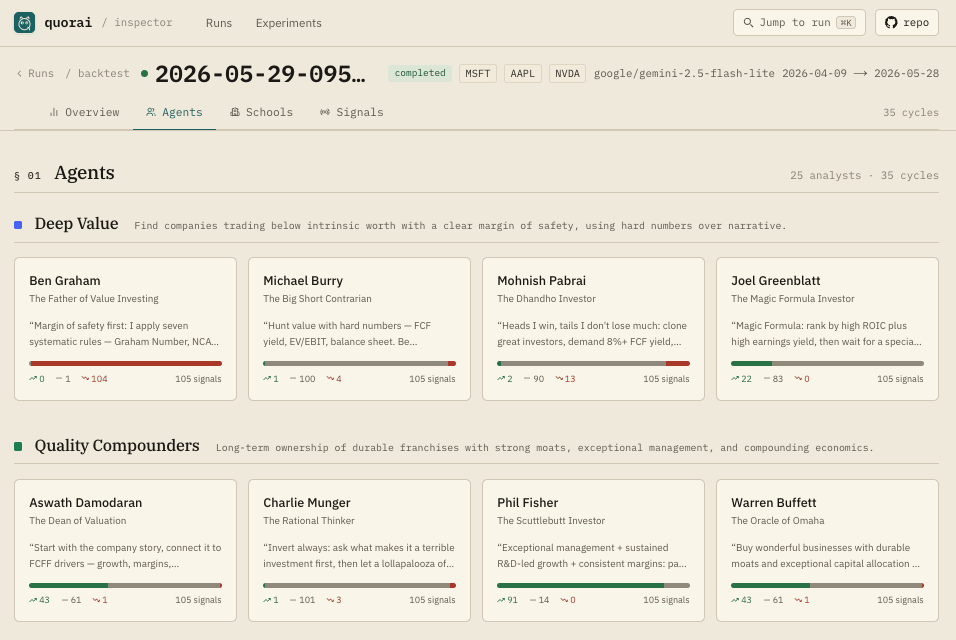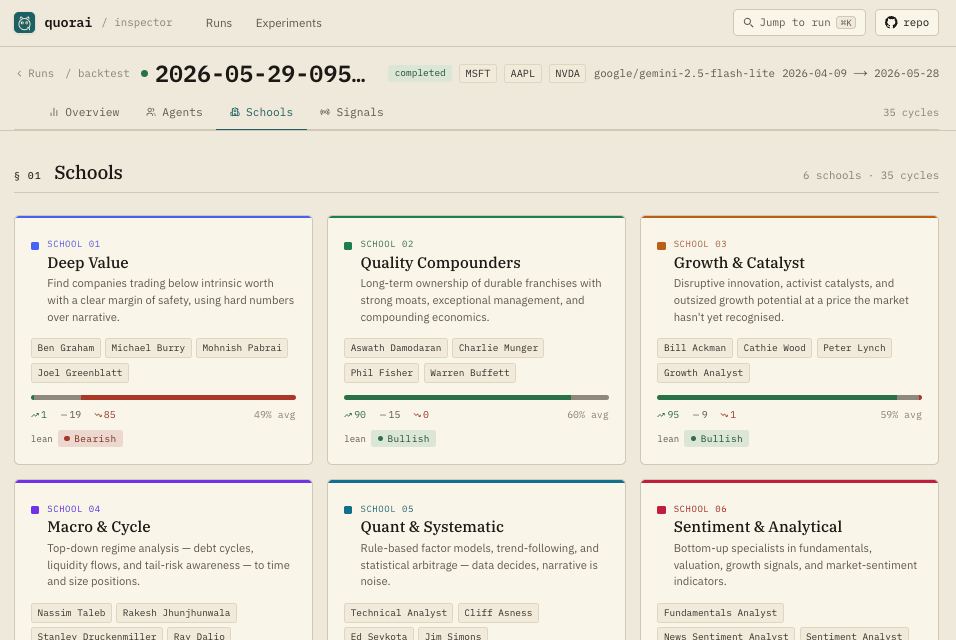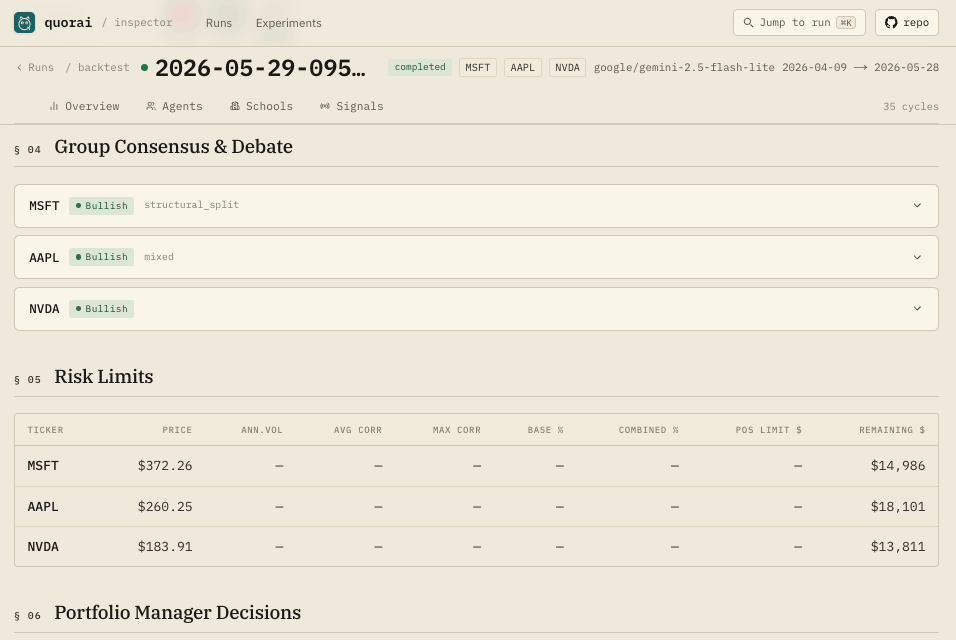
Six main views:
The app also ships a command palette (keyboard-driven navigation across
runs) and uses the same paper / lab-notebook design language as the main repo. Setup
requires only a single env var (QUORAI_LOGS_DIR) pointing at
quorai-app's logs/ directory.